딥 러닝이란 무엇인가?
딥러닝이란 무엇인가?
다층프로세스 계층에 기반한 인공 신경망 네트워크.
머신러닝이란 무엇인가?
사물이나 데이터를 숫자로 바꾸고, 그 숫자에서 패턴을 찾는 기술이다.
컴퓨터가 코드나 수학을 통해 그 작업을 수행한다.
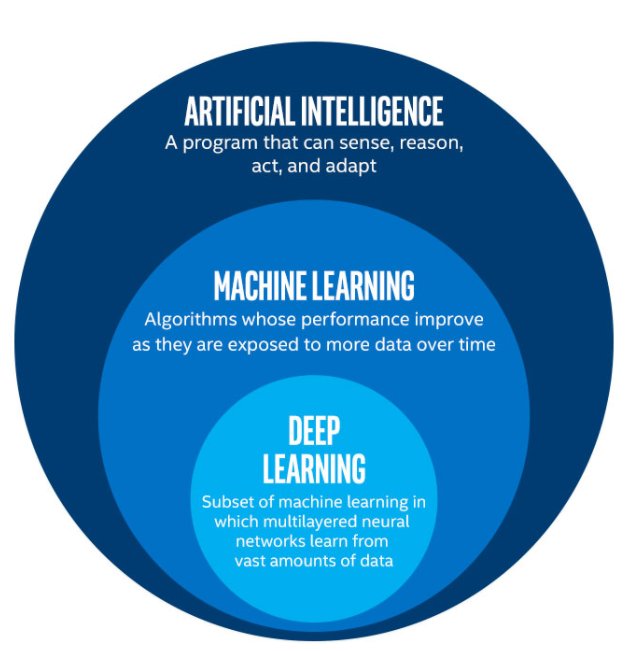
인공지능 하위에 머신러닝이 있고 그 하위에 딥러닝이 있다.
전통적 프로그램과 머신러닝, 딥러닝 프로그래밍의 차이는 무엇인가?
전통적 프로그래밍에서는 인풋코드를 통해 아웃풋을 만들어 낸다.
ml/dl 알고리즘에서는 인풋데이터에 대해 알려주고, 그 이상적 결과물에 대해 알려준다.
왜 머신러닝, 딥러닝을 사용하는가?
만약 자율주행차의 코드를 짜라고 한다면, 그 모든 규칙들을 설계할 수 있겠는가?
숫자와 패턴으로 번역할 수 있는 한, 우주 만물에 대해 머신러닝 할 수 있다.
또한 매일 급변하는 환경속에서 딥러닝을 통해 빠르게 새로운 시나리오를 채택하거나 배울 수 있다.
딥러닝을 적용하기 안좋은 경우.
-명확한 설명이 필요한 경우
딥러닝모델에 의해 학습된 패턴은 일반적으로 인간에 의해 해석 불가능 하기 떄문에 적절하지 않다고 할 수 있다.
-간단한 규칙기반 시스템으로 목표 달성이 달성가능
굳이 ML/DL이 필요가 없다.
-에러가 발생하면 안될때
딥러닝의 결과물이 항상 예측 가능한 건 아니다.
결과물의 반복이 필요할때는 오히려 안 좋을 수가 있다.
머신러닝 vs 딥러닝
전통적 머신러닝은 구조화된 데이터에서 일반적으로 최대의 성능을 낸다.
구글이나 엑셀 스프레드 시트. 딥러닝은 자연어나 텍스트 도형등 비구조화된 데이터에서 최대의 성능을 낸다.
머신러닝 관련 알고리즘.
Random forest
naive bayes
nearest neighbor
support vector machine
등등
딥러닝이 등장한 이후로 이런 알고리즘은 보통 shallow 알고리즘이라 불린다.
딥러닝 관련 알고리즘.
뉴럴 네트워크
완전 연결 뉴럴 네트워크
나선형 뉴럴 네트워크
회귀 신경망
transformer architecture
이 알고리즘들은 수십년동안 다른 딥러닝알고리즘의 기반이 되었다.
하지만 이 알고리즘은 어떻게 문제를 정의하는가에 따라 분류를 넘나들어 쓰이기도 한다.
신경망이란 무엇인가?
뉴런의 회로나 연결을 말하며 현대적 의미에서는 인공신경과 노드로 이루어진 인공 노드네트워크를 말한다.
비구조화된 데이터를 숫자로 번역하게 된다 (nemerical encoding) (tensor)
이 숫자화 된 데이터를 신경망에 넣으면, 이 신경망은 패턴, 특성, 가중치등을 학습하기 시작한다.
데이터를 가공할 신경망은 목적에 따라 채택할 수 있다.
이후 이러한 숫자. tensor의 output으로써 표현값을 만든다.
이 표현값을 바탕으로 라벨링 작업을 한다.
신경망의 해부
신경망의 첫계층은 입력층이라 불린다. 중
간층에는 히든레이어가 있다.히든레이어는 데이터속에서 패턴을 발견하고,
출력층에서 학습된 대표값이나 예측 확률값을 반환한다.
embedding, weights, feature, representation, feature, vectors 모두 비슷한 의미로 사용된다.
학습의 종류
지도학습. 반지도 학습. 비지도 학습. 전이 학습등이 있다.
만약 라면등 음식의 종류를 식별하는 학습을 시킨다고 가정해보자.
지도학습에서는 전부 라벨링된 음식의 이미지를 학습시킨다.
반지도학습에서는 지도학습에 준하는 데이터량이 있지만, 라벨의 매핑은 덜 되어 있다. 즉 라벨링 안된 이미지에 라벨링을 하게 된다.
비지도 학습에는 데이타만 있고 라벨이 없다.
머신러닝이나 딥러닝, 뉴럴 네트워크에 데이터를 입력시켜
어떤 데이터든 결과를 출력해 낸다.
전이 학습은 딥러닝의 꽃이라 할 수 있는데, 다른 학습에서 출력한 패턴을 다른 문제에 다시 적용시키는 것이다.
딥러닝은 무엇을 위해 사용되는가.
누메리컬 인코딩 -> 모델을 통한 학습과 라벨링
딥러닝의 사용케이스
유튜브의 추천기능, 구글 번역기의 번역기능, 음성 인식기능, 컴퓨터 비전, 자연어처리, 등
-유튜브는 브라우징 히스토리를 기반으로 추천한다.
-구글 번역시스템은 문장의 패턴을 딥러닝으로 학습해 대상 언어로 번역하게 된다.
-음성시스템에서는 음파를 언어로 번역.
-자연어처리 이메일의 스펨을 처리하는 시스템 등이 있다.
구글 번역시스템과 음성 시스템은 각각 단어 시퀀스를 다른 단어 시퀀스로 번역하는,
음성 시퀀스를 다른 단어 시퀀스로 번역하는 시퀀스 투 시퀀스 라고 볼 수 있다.
컴퓨터 비전이나 자연어 처리에서는 분류와 회귀를 사용한다.
다중의 분류를 수행한 후 회귀를 하게 되는데
이러한 회귀는 숫자 예측에 좀 더 적합하다고 알려져 있다.
컴퓨터 비전 알고리즘, 객체감지 알고리즘은 객체가 있다고 생각되는 곳의 좌표에 박스를 그린다.